In this penultimate post about the stack, we take a quick look at tail calls, compiler optimizations, and the proper tail calls landing in the newest version of JavaScript.
A tail call happens when a function F makes a function call as its final
action. At that point F will do absolutely no more work: it passes the ball to
whatever function is being called and vanishes from the game. This is notable
because it opens up the possibility of tail call optimization: instead of
creating a new stack frame for the function call, we can simply reuse
F's stack frame, thereby saving stack space and avoiding the work involved in
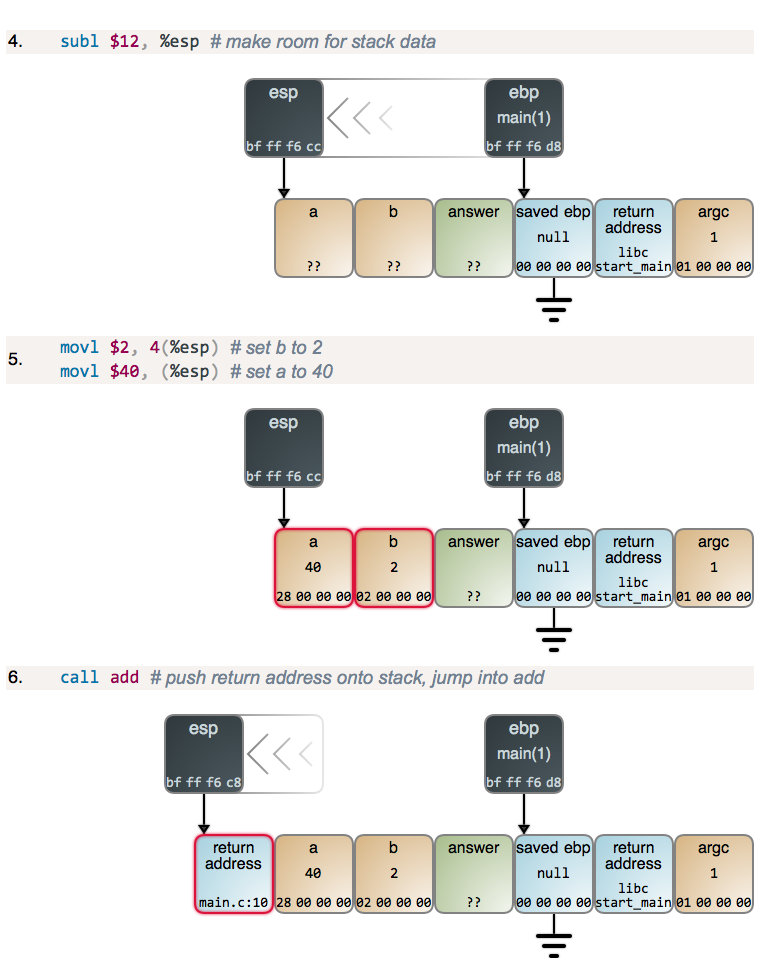
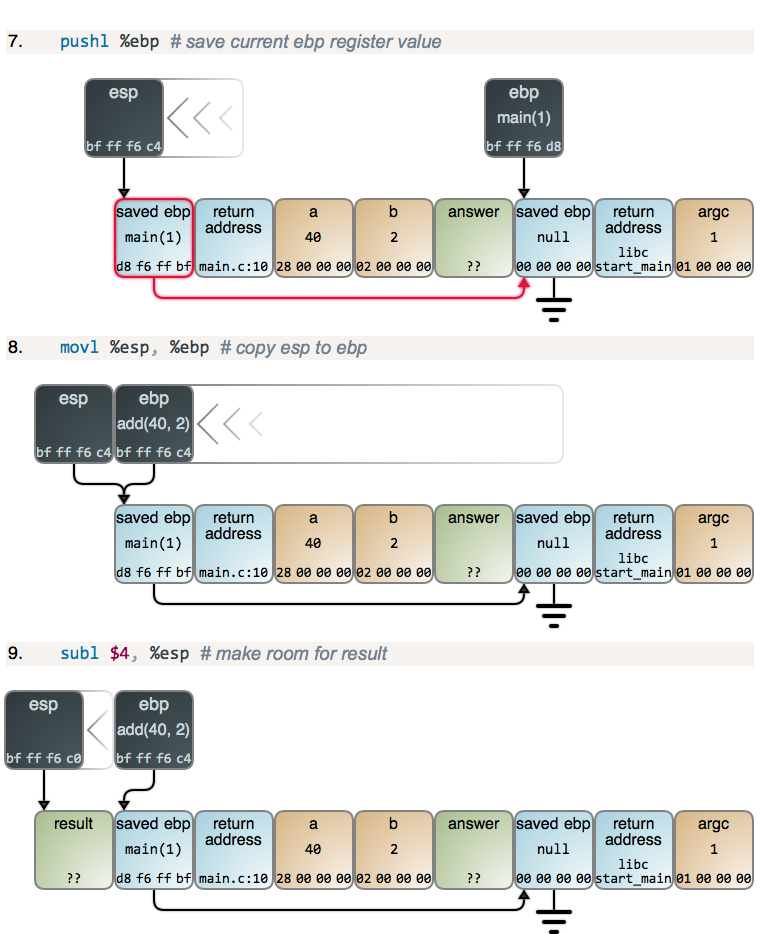
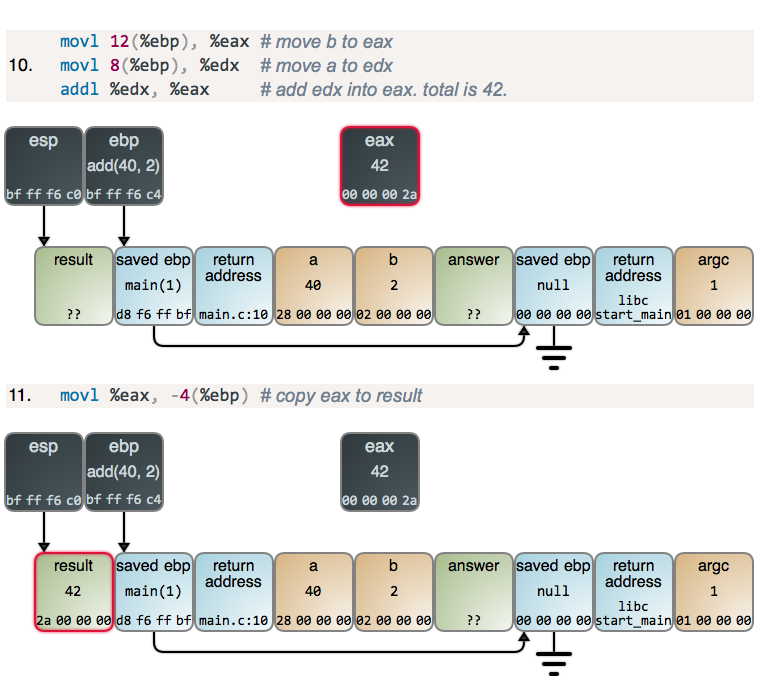
setting up a new frame. Here are some examples in C and their results compiled
with mild optimization:
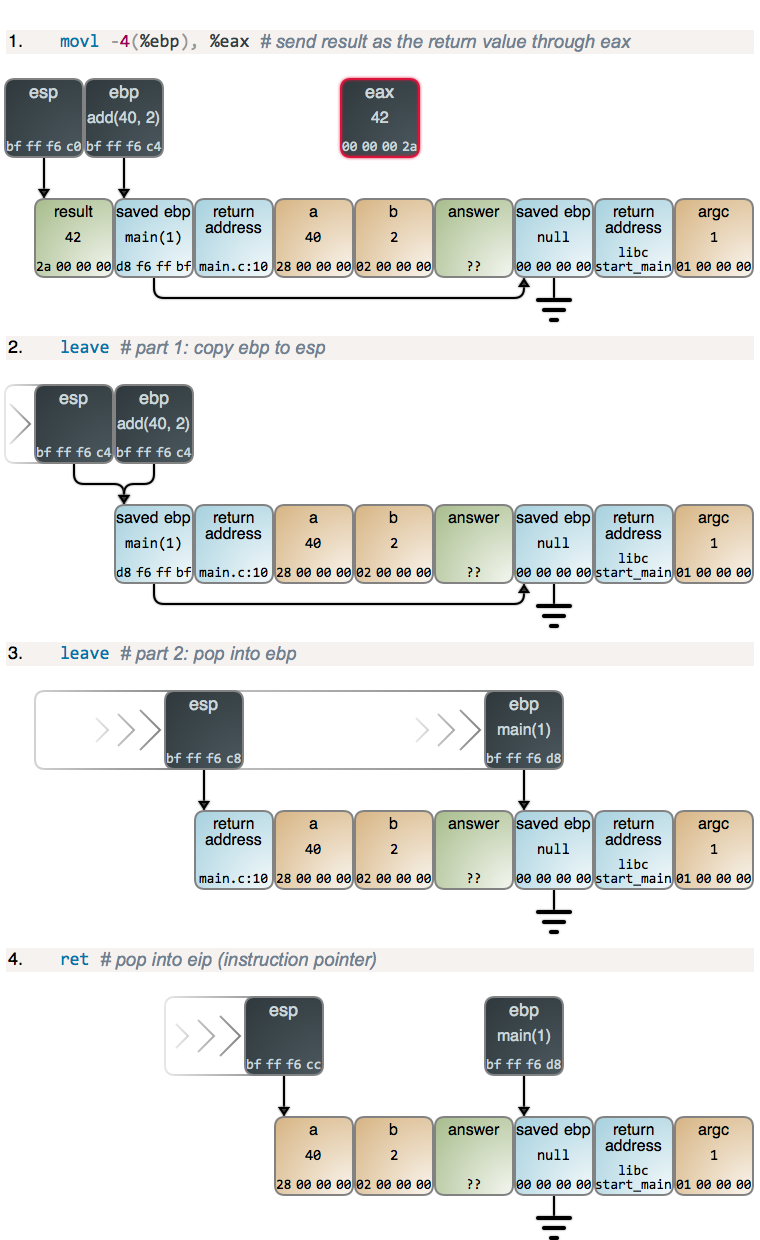
1 | int add5(int a) |
You can normally spot tail call optimization (hereafter, TCO) in compiler output by seeing a jump instruction where a call would have been expected. At runtime TCO leads to a reduced call stack.
A common misconception is that tail calls are necessarily
recursive. That’s not the case: a tail call may be recursive,
such as in finicky() above, but it need not be. As long as caller F is
completely done at the call site, we’ve got ourselves a tail call. Whether it
can be optimized is a different question whose answer depends on your
programming environment.
“Yes, it can, always!” is the best answer we can hope for, which is famously the case for Scheme, as discussed in SICP (by the way, if when you program you don’t feel like “a Sorcerer conjuring the spirits of the computer with your spells,” I urge you to read that book). It’s also the case for Lua. And most importantly, it is the case for the next version of JavaScript, ES6, whose spec does a good job defining tail position and clarifying the few conditions required for optimization, such as strict mode. When a language guarantees TCO, it supports proper tail calls.
Now some of us can’t kick that C habit, heart bleed and all, and the answer there is a more complicated “sometimes” that takes us into compiler optimization territory. We’ve seen the simple examples above; now let’s resurrect our factorial from last post:
1 |
|
So, is line 11 a tail call? It’s not, because of the multiplication by n
afterwards. But if you’re not used to optimizations, gcc’s
result with O2 optimization might shock you: not only it
transforms factorial into a recursion-free loop, but the
factorial(5) call is eliminated entirely and replaced by a
compile-time constant of 120 (5! == 120). This is why debugging optimized
code can be hard sometimes. On the plus side, if you call this function it will
use a single stack frame regardless of n’s initial value. Compiler algorithms
are pretty fun, and if you’re interested I suggest you check out
Building an Optimizing Compiler and ACDI.
However, what happened here was not tail call optimization, since there was
no tail call to begin with. gcc outsmarted us by analyzing what the function
does and optimizing away the needless recursion. The task was made easier by
the simple, deterministic nature of the operations being done. By adding a dash
of chaos (e.g., getpid()) we can throw gcc off:
1 |
|
Optimize that, unix fairies! So now we have a regular recursive call and this function allocates O(n) stack frames to do its work. Heroically, gcc still does TCO for getpid in the recursion base case. If we now wished to make this function tail recursive, we’d need a slight change:
1 |
|
The accumulation of the result is now a loop and we’ve
achieved true TCO. But before you go out partying, what can we say about the
general case in C? Sadly, while good C compilers do TCO in a number of cases,
there are many situations where they cannot do it. For example, as we saw in our
function epilogues, the caller is responsible for cleaning up the
stack after a function call using the standard C calling convention. So if
function F takes two arguments, it can only make TCO calls to functions taking
two or fewer arguments. This is one among many restrictions. Mark Probst wrote
an excellent thesis discussing Proper Tail Recursion in C where he
discusses these issues along with C stack behavior. He also does
insanely cool juggling.
“Sometimes” is a rocky foundation for any relationship, so you can’t rely on TCO in C. It’s a discrete optimization that may or may not take place, rather than a language feature like proper tail calls, though in practice the compiler will optimize the vast majority of cases. But if you must have it, say for transpiling Scheme into C, you will suffer.
Since JavaScript is now the most popular transpilation target, proper tail calls become even more important there. So kudos to ES6 for delivering it along with many other significant improvements. It’s like Christmas for JS programmers.
This concludes our brief tour of tail calls and compiler optimization. Thanks for reading and see you next time.





{kind=link}
{kind=link}